



Ep.7 How does China conduct AI safety testing?
How CAICT is shaping AI governance with a focus on present-day risks rather than AGI catastrophe

While Western AI safety discourse centers on preventing future AGI catastrophes, China has taken a markedly different approach. The China Academy of Information and Communications Technology (CAICT) AI Safety Governance team has emerged as the key institution testing and regulating Chinese frontier AI models—but their priorities tell a fascinating story about divergent safety philosophies.
The Great Divide in AI Safety Philosophy
The contrast is stark. Western AI safety frameworks, like the EU's Code of Practice, focus on preventing catastrophic outcomes that could "threaten the health, safety, and fundamental rights of many people." They worry about AI systems that might:
discovering vulnerabilities in computer code (including previously unknown ones);
lowering barriers to biological and chemical weapons development for both novices and experts;
being capable of effective, targeted psychological manipulation; and
trying to resist being shut down in certain circumstances and generating answers that falsely suggest alignment with goals provided by its developers.
In sharp contrast, Chinese safety evaluations are laser-focused on present-day risks and specific use-case scenarios. Rather than asking "How do we prevent AI from destroying humanity?" they're asking "How do we ensure AI safely serves current societal needs?" This aligns with the Chinese government's long-standing regulatory logic for AI safety governance, which can be summarized as: flexibility over formalism, gradualism over sweeping reform, and prioritizing controllability in real-world applications over preventing distant future risks.
Meet CAICT: China's AI Safety Gatekeeper
The CAICT AI Safety Governance team occupies a unique position in China's AI ecosystem. As a government-affiliated think tank, they serve as both policy advisors and testers—playing an absolutely central role as core members of China's AI safety network. (Unlike in the West, purely third-party nonprofit testing institutions struggle to survive in China, where the governance model limits NGO development and enterprises aren't accustomed to collaborating with NGOs.)
Systematic Compliance Consulting: They help companies navigate Chinese AI regulations, covering everything from corpus safety to model output monitoring, combining both consulting and auditing functions.
Professional Security Testing: They conduct model safety evaluations based on the "Basic Security Requirements for Generative AI Services," helping companies identify potential issues before deployment.
Customized Compliance Support: Their multidisciplinary team of legal and computer science experts provides ongoing compliance monitoring and filing support.
What's particularly noteworthy is their promise of 1-2 month service completion, with both online and offline support for enterprises. This isn't just administrative oversight—it's an institutional design aimed at accelerating compliant enterprise deployment.


The Numbers: China's 2025 AI Safety Benchmark
CAICT recently released results from their Q1 2025 AI Safety Benchmark, conducted with over 30 organizations. Unlike Western evals focused on existential risks, this benchmark tackles a very practical problem: hallucinations.
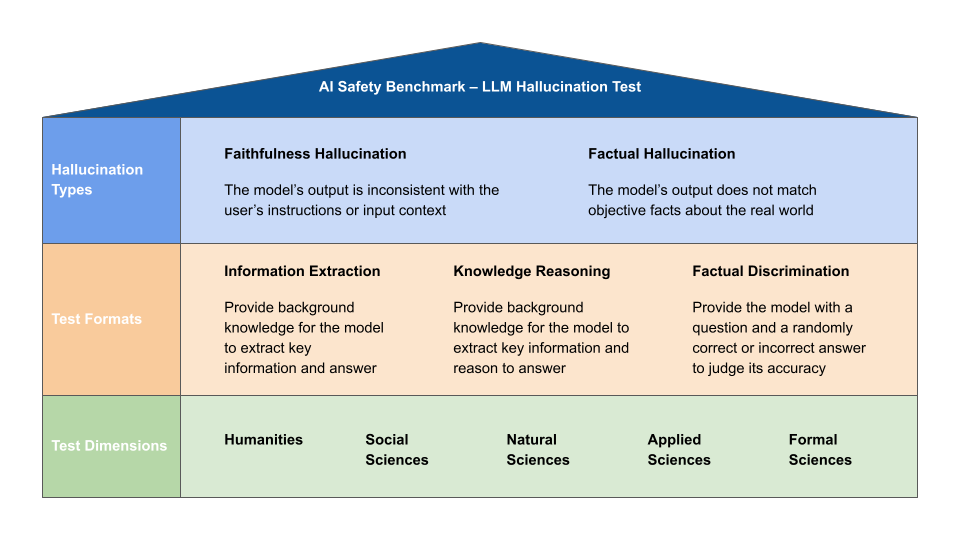

The Test Setup
They evaluated 15 models across two categories:
10 general-purpose models: Including Qwen variants, ERNIE-4.5, DeepSeek-V3, and GLM-4-Plus
5 reasoning models: Including QwQ-32B, DeepSeek-R1, and GLM-Z1-Air
The evaluation used over 5,000 test cases across five knowledge domains, measuring both factual accuracy and instruction fidelity.
Test Result 1: Overall Hallucination Rate

Key Findings
1. Universal Problem: Every model exhibited hallucinations to varying degrees, with factual hallucination rates consistently higher than fidelity hallucination rates across all tested systems. This suggests fundamental limitations in current model architectures' ability to maintain factual accuracy.
2. Domain-Specific Performance Variations: Models demonstrated significantly better performance in formal sciences (exhibiting lower factual hallucination rates), indicating stronger capabilities in logic and symbolic reasoning tasks. Conversely, fidelity hallucinations were lowest in applied sciences but markedly higher in formal sciences and humanities, suggesting domain-dependent consistency patterns.
3. Parameter Scale Effects: Systematic comparison of seven models from the same open-source series revealed an inverse correlation between parameter count and hallucination rates. This finding has direct implications for deployment decisions, as larger models demonstrate measurably improved reliability at the cost of computational resources.
4. Knowledge Distillation Trade-offs: Comparative analysis between base models and their distilled counterparts revealed that student models consistently exhibited higher fidelity hallucination rates than their teacher models. This suggests that knowledge compression processes may compromise instruction-following consistency while potentially preserving factual knowledge.
5. Reasoning Enhancement Limitations: While reasoning-enhanced models showed statistically significant reductions in hallucination rates compared to general-purpose models—particularly for factual accuracy—they did not eliminate the underlying problem. This indicates that current reasoning methodologies provide meaningful but incomplete solutions to hallucination challenges.
What This Reveals About Chinese AI Strategy
The focus on hallucinations over existential risk reveals several strategic priorities:
Practical Deployment: China wants AI systems that work reliably today, not theoretical safeguards against speculative futures.
Economic Integration: By streamlining compliance and focusing on deployment-ready metrics, they're optimizing for AI economic integration.
Controlled Innovation: The advisor-enforcer model allows rapid innovation within clearly defined boundaries—classic Chinese tech governance.
The Road Ahead
CAICT isn't stopping at hallucinations. Their roadmap includes:
Industry-specific hallucination testing
Multimodal model evaluation methods
Automatic detection and mitigation tools
Ongoing benchmark iterations
This represents a fundamentally different bet on AI safety priorities. While Western labs pour resources into preventing AI takeover scenarios, Chinese institutions are systematically improving AI reliability for immediate applications.
The Bigger Picture
What's certain is that China isn't simply "following" Western AI safety practices, but rather building a governance framework optimized for its own strategic priorities and real-world effectiveness. While the EU Code of Practice addresses more fundamental and cutting-edge risk issues, China's current institutional advantage lies in its state-led approach to safety testing, which ensures that enterprises receive clear safety signals and follow through with testing compliance.
This may prove more reliable in the AI safety domain than "market-driven" safety measures. When every company must pass the same safety assessments, a baseline level of security is guaranteed across the entire ecosystem.
The Chinese government's risk aversion and preference for stability manifests as a "control first, develop second" gradualist pathway when facing emerging technologies. For example, in military applications, the Chinese military would likely deploy AI with much greater caution. This approach constitutes an alternative pathway for AI safety.