Chatbot Arena leaderboard
Chinese LLM models generally lag behind their US counterparts. The table below shows the top 20 models from the Chatbot Arena leaderboard. This platform provides real-world usage evaluations of LLMs through anonymous, randomized comparisons that resist artificially inflated scores. Chinese models are highlighted in red. Only the best-performing model from each company is included.

Chinese organisations in this leaderboard:
Chinese AI company founded in March 2023 by Kai-Fu Lee, a former executive at Microsoft and Google
Valuation: $1 billion (unicorn)
Compute provider: Turing Inno [1], Chinese company specializing in artificial intelligence (AI) infrastructure and services
Chinese AI company founded in 2019 as a spin-off from Tsinghua University
Valuation: $3 billion (unicorn)
Compute provider: PARATERA [2], Chinese company specializing in high-performance computing (HPC) and cloud services
Alibaba
Chinese big tech company founded in 1999 by Jack Ma
Valuation: $200 billion (publicly traded)
Compute provider: Alibaba Cloud, No. 1 cloud compute service in the Asia-Pacific region with a 21.3% market share [3]
Advanced AI platform developed by High-Flyer Capital Management, a Chinese quantitative hedge fund
Valuation: N/A (not publicly traded)
Compute provider: High-Flyer Capital Management
New Developments in Reasoning
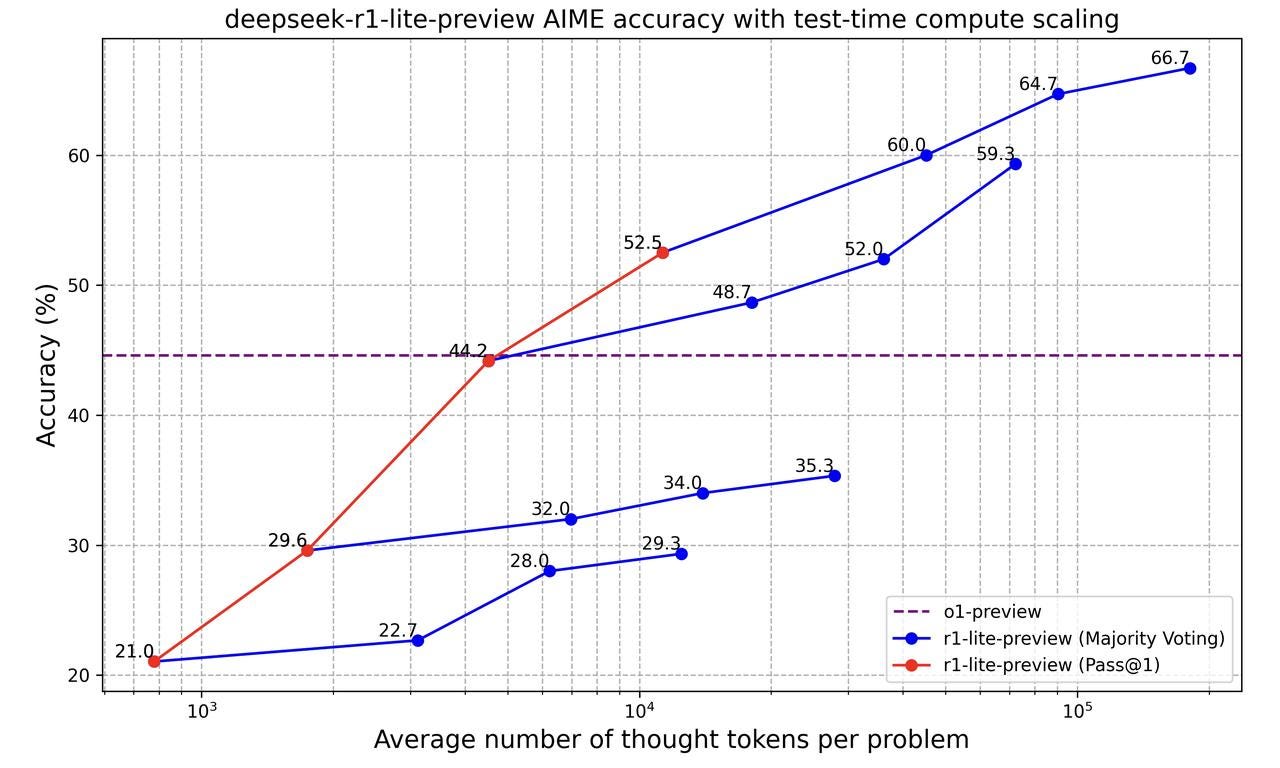
A significant recent advancement is that Chinese models are developing reasoning capabilities comparable to OpenAI's o1 models. Two notable examples are "k0_math" by Moonshot AI and "DeepSeek_R1_Lite" by DeepSeek. To assess this progress, a highly challenging math benchmark—the American Invitational Mathematics Examination (AIME)—was used. This benchmark is particularly valuable for comparison because most models nowadays excel at standard math benchmarks, making it difficult to differentiate their capabilities.

These data were produced by the companies that created these models. Despite these advancements, Chinese models still lag significantly behind the official release of OpenAI's o1, which boasts an impressive AIME score of 83.8. While testing methodologies may vary slightly, this comparison offers a solid approximation of the current capabilities gap.
Appendix: technical details on new reasoning models
Note: The following benchmarking results presented for k0_math and DeepSeek-R1-Lite models against OpenAI's o1 are derived from marketing materials published by the respective Chinese model companies. While these comparisons provide insights into the progress of Chinese AI models, it's important to consider that they may not have been independently verified and could potentially be subject to marketing bias.
k0_math

DeepSeek-R1-Lite